随着科技浪潮的不断推进,硬件迭代的速度日益加快,每一次更新不仅意味着数字上的跃升,更预示着应用场景的深刻变革。近期,两大显卡巨头NVIDIA与AMD相继发布了全新的消费级显卡系列——NVIDIA GeForce RTX 50系列与AMD Radeon RX 9070系列,引发了业界的广泛关注与讨论。
与以往不同,此次发布的显卡除了在游戏性能上有所提升外,更加引人注目的是它们在人工智能(AI)算力方面的显著增强。AI,这一曾经遥不可及的词汇,如今正以前所未有的速度渗透到我们数字生活的方方面面,从视频编辑中的智能对象抠图、音频降噪,到3D渲染中的AI辅助优化,再到本地运行大型语言模型(LLM)的潜力,无一不彰显着AI的强大力量。

消费级显卡的设计理念正经历着一场深刻的变革。它们不再仅仅局限于驱动极致游戏画面的“游戏卡”,而是越来越多地承担起内容创作加速、复杂科学计算,乃至驱动前沿AI模型的重任。这一转变,无疑对底层硬件的AI处理能力提出了更高的要求。

在各大科技媒体和独立评测机构的评测报告中,除了常规的3DMark、游戏帧率等数据外,一系列专业的AI基准测试工具及其得分也成为了衡量显卡性能的重要指标。这些工具,如MLPerf、UL Procyon AI Inference Benchmark等,正成为衡量显卡“智慧”程度的标尺。
AI,特别是深度学习,其核心运算大多涉及大规模的矩阵和向量运算。而GPU,这一最初为图形渲染而设计的硬件,其核心优势在于拥有数千个小型计算核心,能够同时执行大量并行计算任务,这一特性与AI算法的需求不谋而合,使得GPU在处理AI任务时远比CPU更高效。

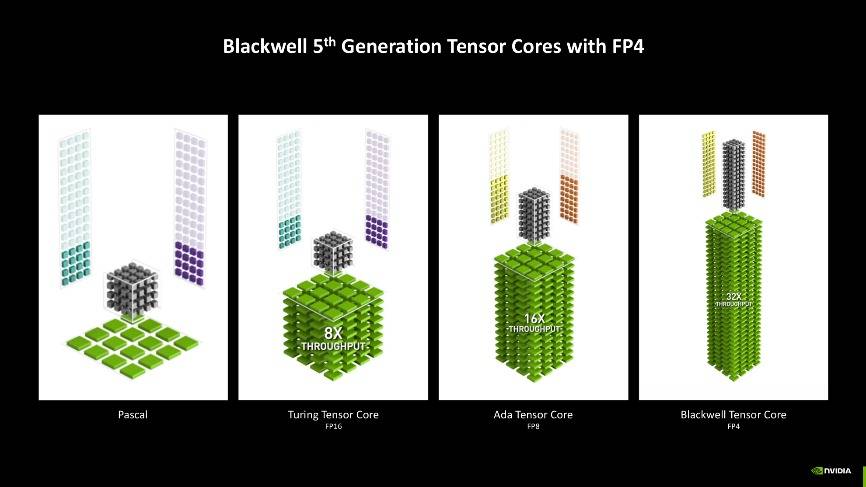
以新一代消费显卡技嘉GeForce RTX 5070 Ti GAMING OC 魔鹰 16G为例,其采用了先进的TSMC 4nm制造工艺,核心规格与性能都有着明显的提升,尤其是在AI性能方面。该显卡支持FP4精度模型加速处理,相较FP8精度,能够实现更快的生成速度,同时显存占用也更低。从实际测试来看,FP4精度模型生成的图片质量与FP8几乎无异,无论是关键词的理解还是图像的质量,都表现得相当出色。
在AI测试工具的报告中,我们会遇到一系列专业术语和指标,如TOPS/FLOPS(理论峰值算力)、吞吐量(Throughput)、延迟(Latency)、准确性(Accuracy)以及能效比(Performance per Watt)等。这些指标对于衡量显卡的AI性能至关重要。例如,TOPS/FLOPS作为衡量GPU理论计算潜力的关键指标,通常由芯片制造商公布;而吞吐量则指单位时间内系统能够处理的AI任务数量,高吞吐量意味着显卡能够高效处理大规模AI任务。
在AI基准测试工具方面,MLPerf和UL Procyon AI Benchmark是两款备受关注的测试套件。MLPerf是一套行业标准基准测试套件,旨在公平、客观地评估机器学习系统的性能;而UL Procyon AI Benchmark则是一套专业基准测试套件,涵盖了AI计算机视觉、图像生成以及文本生成等多个方面的测试。通过这些测试工具,我们可以更加准确地评估显卡在AI时代的真实价值。
以技嘉GeForce RTX 5070 Ti GAMING OC 魔鹰 16G显卡为例,在MLPerf Client的测试中,该显卡在llama-2-7b-chat-dml模型上的表现相当出色,First Token响应时间与Token平均生成速度都达到了较高的水平。而在UL Procyon AI Benchmark的测试中,该显卡在计算机视觉、图像生成以及文本生成等多个方面也都展现出了强大的性能。





















