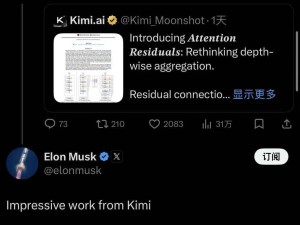
当全球AI行业陷入“参数规模竞赛”与“应用层同质化”的双重困局时,一家成立仅五年的中国AI公司——月之暗面(Moonlight AI),凭借对Transformer架构核心机制的颠覆性改造,意外获得科技界“风向标”埃隆·马斯克的公开认可。其旗下Kimi团队在论文中提出的“动态注意力残差连接”方案,直指深度学习领域长达十一年的技术禁区,为行业突破“模型效率瓶颈”提供了全新路径。
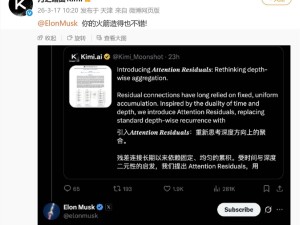
Transformer架构自2015年问世以来,其“注意力机制”与“残差连接”构成的双重支柱,支撑起从BERT到GPT-4的历代语言模型。但Kimi团队研究发现,随着模型参数规模突破万亿级,标准残差连接的“加法操作”正导致深层特征被浅层特征系统性稀释——这一现象被学术界称为“PreNorm稀释效应”。团队首席科学家张弛比喻道:“就像用清水稀释墨汁,模型堆叠的层数越多,最终输出的‘颜色’反而越淡,丢失了最关键的语义细节。”
面对这一困扰行业多年的难题,Kimi团队提出用“动态注意力机制”重构残差连接逻辑。新方案不再简单叠加各层特征,而是通过计算不同层级特征的注意力权重,实现“重要特征强化保留、冗余信息动态过滤”。为解决计算开销问题,团队创新性地采用“块注意力”技术,将特征矩阵分块处理,使内存占用降低60%的同时保持模型精度。实验数据显示,在同等参数规模下,采用新架构的模型推理速度提升30%,训练成本下降25%,在医疗文本分析、法律合同解读等长文本场景中表现尤为突出。
这项突破之所以引发震动,在于其触及了AI基础架构的“不可动摇部分”。自2017年OpenAI首次将残差连接引入语言模型以来,谷歌、meta等巨头虽尝试过调整连接位置或添加权重参数,但始终未敢改变“加法操作”这一底层设计。Kimi团队的数学证明显示,现有主流残差变体(包括PreNorm、PostNorm)均是其方案在“注意力权重均匀分布”时的特例,这意味着他们为Transformer架构提供了更普适的理论框架。
在商业层面,月之暗面的崛起轨迹同样引发关注。这家2021年成立的公司,在2023年推出Kimi大模型时曾被质疑“模仿ChatGPT”,但通过聚焦企业级市场,迅速积累起字节跳动、宁德时代等5000余家客户。2025年完成D轮融资后,其估值突破300亿元人民币,红杉中国、高瓴资本等顶级机构的持续加注,为其基础研究提供了充足弹药。公司CTO在内部信中透露:“我们每年将40%的营收投入底层技术研发,这个比例在行业中属于绝对少数。”
马斯克的罕见认可,为这场争论增添了新的维度。这位以“技术洁癖”著称的科技领袖,此前曾多次批评行业巨头“沉迷于规模竞赛”,此次却用“Interesting approach”评价Kimi的方案。科技分析师Avi Chawla指出:“这标志着中国AI公司首次在深度学习‘根技术’层面获得国际认可,其意义不亚于华为5G对通信行业的冲击。”
目前,Kimi团队已将新架构开源,并推出适配不同场景的变体版本。尽管有研究员提醒“基础创新需要长期验证”,但不可否认的是,当行业集体陷入“堆参数、卷应用”的循环时,这种直面技术本质的探索,正在为AI发展开辟新的可能性。正如张弛所言:“我们不是在推倒重来,而是为这座已经运行十年的‘超级机器’更换更精密的齿轮——这或许比建造新机器更难,但值得尝试。”