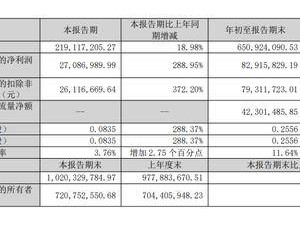
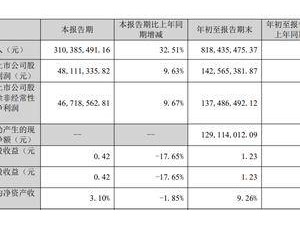
全球互联网近日经历了一场意想不到的震荡,大量用户突然发现无法正常访问网站,社交媒体瞬间被相关话题刷屏。这场风波的源头,竟是知名网络安全服务提供商Cloudflare的一次意外故障。
作为全球领先的网站安全与性能优化服务商,Cloudflare的客户群体覆盖了从个人博主到跨国企业的广泛范围。其核心服务包括抵御分布式拒绝服务攻击(DDoS)和加速网站访问速度,因此被众多互联网平台视为重要基础设施。然而这次故障却让全球依赖其服务的网站集体"瘫痪",影响范围之广令人咋舌。
根据Cloudflare官方披露的技术细节,故障源于某个数据中心的操作配置失误。这个局部错误通过其全球网络迅速扩散,最终导致服务中断。从个人博客到知名社交媒体,从中小企业网站到跨国电商平台,无数用户遭遇了访问异常,部分平台甚至完全无法加载。
故障发生后,社交媒体上涌现出大量用户反馈。"网站打不开了!""到底发生了什么?"类似的困惑和焦虑充斥着各个平台。有博主焦急地询问:"我的个人网站突然无法访问,这会影响我的流量吗?"更有企业主担忧:"我们的在线服务中断会不会造成客户流失?"
面对这场危机,Cloudflare的技术团队立即启动应急响应机制。公司通过官方渠道持续更新故障处理进展,技术团队争分夺秒地定位问题根源。经过数小时的紧急修复,服务逐步恢复正常,但这次事件已在互联网行业引发深刻反思。
行业专家指出,这次故障暴露出两个关键问题:首先,即使是最成熟的技术系统也存在脆弱性;其次,过度依赖单一服务提供商可能带来系统性风险。许多企业开始重新审视自己的网络架构,考虑建立多层次的安全防护体系和应急预案。
对于普通用户而言,这次事件最直观的感受是互联网世界的相互依存性。一个看似遥远的数据中心配置错误,竟能在短时间内影响全球数十亿用户的上网体验。这也提醒人们,在享受数字技术便利的同时,必须重视网络基础设施的稳定性建设。
Cloudflare在事后发布的详细技术报告中承诺,将加强内部流程管控,完善全球网络的冗余设计。这次事件虽然造成短暂困扰,但也展现了公司在危机处理中的透明度和响应速度,为行业应对类似事件提供了重要参考。