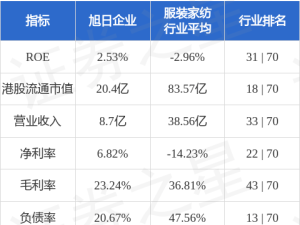
阿里巴巴与新加坡国家人工智能计划联合推出的东南亚多语言大模型Qwen-SEA-LION-v4,近日在东南亚语言模型评估基准SEA-HELM开源榜单(参数量2000亿以下组别)中斩获榜首。这款由中新科研团队共同研发的模型,标志着区域性语言处理技术取得突破性进展。
东南亚地区语言生态复杂,现存语言超过1200种,日常交流中多语言混用现象普遍。传统AI模型多以英语为核心构建,难以适应本地化需求,导致区域AI应用长期面临技术壁垒。此次合作研发的Qwen-SEA-LION-v4,正是为破解这一难题而生。该模型以阿里巴巴"通义千问"开源框架为基础,通过针对性优化大幅提升了对东南亚小语种的处理能力。
技术团队在模型构建过程中采取双阶段策略:预训练阶段覆盖119种语言数据,重点强化对缅甸语、马来语、泰米尔语等区域性语言的语义理解;后训练阶段则通过增加跨语言任务权重,使模型能够准确识别混合输入中的不同语言成分。这种设计使模型在处理包含多种语言的复杂文本时,展现出显著优于传统模型的性能表现。
目前该模型已通过新加坡人工智能计划官网及国际开源社区HuggingFace向全球开放下载。研发团队表示,模型开源将加速区域AI生态建设,为东南亚数字经济发展提供底层技术支撑。此次突破不仅验证了中新科技合作的有效性,也为多语言环境下的AI应用提供了新的技术范式。