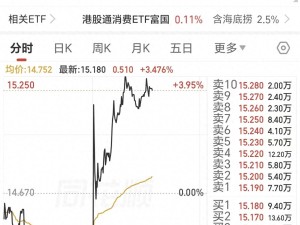
全球开源语言模型领域正经历一场格局重塑,中国科技企业的创新成果正引发广泛关注。据国际权威机构Interconnects AI最新报告显示,截至2026年3月,阿里云旗下通义千问(Qwen)系列模型已占据全球开源模型下载市场半壁江山,累计下载量突破9.8亿次,在Hugging Face等主流平台形成显著领先优势。这一数据不仅超越meta Llama、DeepSeek等国际主流模型,更标志着中国开源生态首次实现历史性突破。
2026年2月成为关键转折点,Qwen系列单月下载量达1.536亿次,相当于同期meta、DeepSeek及OpenAI等八家主要机构下载总和。更值得关注的是,中国开源模型在该月Hugging Face平台的月下载占比达41%,首次超越美国的36.5%。这一突破可追溯至2024年9月Qwen 2.5系列的发布,该版本通过算法优化将部署显存占用降低40%,为开发者提供了更高效的解决方案。
第三方研究机构《ATOM报告》通过多维分析印证了这一趋势。报告指出,中国模型自2025年夏季开始持续扩大领先优势,在衍生模型数量、推理市场份额等指标上形成全面超越。截至2026年3月,千问系列已开源超过400款模型,衍生模型数量突破20万,构建起全球最大的开源生态体系,其生态规模已超越美国Llama系列两倍以上。
技术突破与生态建设形成良性循环。2026年2月发布的Qwen 3.5系列将部署显存占用进一步压缩60%,同时将API价格降至每百万Token 0.8元,仅为国际同类产品的三分之一。这种"技术普惠"策略吸引全球开发者加速迁移,目前已有超过300万开发者基于千问架构开发应用,覆盖智能客服、内容生成、科研辅助等20余个领域。
行业格局变化背后折射出战略路径分野。面对中国开源生态的崛起,meta于2026年宣布全面转向闭源路线,推出旗舰模型Muse Spark。这种转变使meta失去在开源社区的先发优势,而中国科技企业则通过"开源+商业闭环"模式开辟新赛道。目前,千问系列已形成"基础模型开源-行业应用闭源"的分层架构,既保持生态开放性,又通过定制化服务实现商业价值转化。
全球开发者社区正经历深刻变革。Hugging Face平台数据显示,中国开发者贡献的开源项目占比从2023年的18%跃升至2026年的37%,在多模态处理、长文本理解等前沿领域形成技术集群。这种集体创新模式使中国开源生态展现出强大韧性,即便在国际环境变化的背景下,仍保持每月15%的模型迭代速度。